R Dirty Data
What is dirty data?
From wikipedia, dirty data, is inaccurate, incomplete or erroneous data, which can contain such mistakes as spelling or punctuation errors, incorrect data associated with a field, incomplete or outdated data, or even data that has been duplicated in the database. It can be cleaned through a process known as data cleansing.
脏数据是不准确的,不完整或错误的数据,它们可能包含拼写或标点符号错误,与研究领域相关的错误数据,不完整的或过时的数据,甚至是数据库中重复的数据。 它可以通过一个称为数据清理的过程进行清理。
Dirty Data 包括:
- MCAR - 完全随机缺失(missing complete at random, 缺失与研究对象无关)
- MAR - 随机缺失(missing at random, 缺失与研究对象有关)
- NMAR - 非随机、不可忽略缺失(not missing at Random, or nonignorable)
NAs in R
NA(meaning not applicable, not available, or no answer) NA which cantains NA_integer_, NA_real_, NA_complex_ and NA_character_, can be coerced to any other vector type except raw.
Manipulate NAs
1/0 # Inf 0/0 sqrt(-1) 1/0 - 1/0 # NaN not a number NaN > NA # NA x <- c(NA,Inf,NaN,0,NULL) # NULL means that there is no value is.na(x) # support type list or vector # TRUE FALSE TRUE FALSE is.nan(x) # FALSE FALSE TRUE FALSE is.infinite(x) # FALSE TRUE FALSE FALSE is.null(x) # FALSE x <- c(NA,Inf,NaN,0,"NA") is.na(x) # TRUE FALSE FALSE FALSE FALSE # Coz NaN will coerced to a string like x <- c(NaN,"") is.na(x) <- c(2,4) x # NA NA "NaN" NA "NA" c(TRUE, FALSE) & NA ## NA FALSE c(TRUE, FALSE) | NA # TRUE NA |
df <- data.frame( a=c(TRUE,TRUE,TRUE,FALSE,FALSE,FALSE,NA,NA,NA), b=c(TRUE,FALSE,NA,TRUE,FALSE,NA,TRUE,FALSE,NA)) # This function returns TRUE wherever elements are the same, including NA's, # and FALSE everywhere else. compareNA <- function(v1,v2) { same <- (v1 == v2) | (is.na(v1) & is.na(v2)) same[is.na(same)] <- FALSE return(same) } data.frame(df, isSame = compareNA(df$a,df$b)) # a b isSame # 1 TRUE TRUE TRUE # 2 TRUE FALSE FALSE # 3 TRUE NA FALSE # 4 FALSE TRUE FALSE # 5 FALSE FALSE TRUE # 6 FALSE NA FALSE # 7 NA TRUE FALSE # 8 NA FALSE FALSE # 9 NA NA TRUE |
any(is.na(x)) Vs anyNA(x))
Generally, anyNA(x) is a more faster way
- user time: time charged to the CPU(s)
- elapsed time: “wall clock” time
x <- sample(c(1:10000,rep(NA,100),rep(NaN,100)),10000) N <- 2^20 print(rbind(is.na = system.time(replicate(N, any(is.na(x)))), anyNA = system.time(replicate(N, anyNA(x))))) # user.self sys.self elapsed user.child sys.child # is.na 17.93 11.04 29.05 NA NA # anyNA 0.87 0.00 0.87 NA NA |
Whats more, anyNA can also perform a recursive way
L <- list(c(1:10),c(NA_integer_, NA_real_, NA_complex_ ,NA_character_),c(sqrt(-1),1/0 - 1/0)) sapply(L, anyNA); c(anyNA(L), anyNA(L, TRUE)) ## NaNs produced # FALSE TRUE TRUE # FALSE TRUE |
Ignoring “bad” values in R
v <- c(1, 2, 3, NA, 5, NaN, Inf, NULL ) is.na(v) # FALSE FALSE FALSE TRUE FALSE TRUE FALSE mean(v) sum(v) # NA mean(v, na.rm=TRUE) # 2.75 sum(v, na.rm=TRUE) # Inf sum(v[-7], na.rm=TRUE) # 11 sum(1,2,NA,na.rm = T) # 3 mean(1,2,NA,na.rm = F) # 1!!! v[!is.na(v)] # 1 2 3 5 Inf |
Airquality for example
153 entries:
- Ozone : Ozone (ppb)
- Solar.R : Solar radiation in Langleys (lang)
- Wind : Average wind speed in miles per hour (mph)
- Temp : Maximum daily temperature in degrees Fahrenheit (degrees F)
- Month : Month (1–12)
- Day : Day of month (1–31)
x <- c(1, 2, NA, 4, NA, 5) y <- c("a", "b", NA, "d", NA, "f") good <- complete.cases(x, y) good # TRUE TRUE FALSE TRUE FALSE TRUE y[good] # "a" "b" "d" "f" |
airquality[1:6, ] |
## Ozone Solar.R Wind Temp Month Day ## 1 41 190 7.4 67 5 1 ## 2 36 118 8.0 72 5 2 ## 3 12 149 12.6 74 5 3 ## 4 18 313 11.5 62 5 4 ## 5 NA NA 14.3 56 5 5 ## 6 28 NA 14.9 66 5 6 |
good <- complete.cases(airquality) ## 111 entries airquality[good, ][1:6, ] |
## Ozone Solar.R Wind Temp Month Day ## 1 41 190 7.4 67 5 1 ## 2 36 118 8.0 72 5 2 ## 3 12 149 12.6 74 5 3 ## 4 18 313 11.5 62 5 4 ## 7 23 299 8.6 65 5 7 ## 8 19 99 13.8 59 5 8 |
Simulate a dataset containing undesirable data
Simulate a dataset
df <- data.frame( sex=factor(rep(c("F", "M"), each=200)), weight=round(c(rnorm(200, mean=55, sd=5), rnorm(200, mean=65, sd=5))) ) set.seed(0) # Setting the random number seed with set.seed ensures reproducibility library(openxlsx) Names <- read.xlsx(file.choose())[,1] # import names Name <- paste0(sample(Names,1000,replace = T)) Sex <- factor(sample(c('F','M'),1000, replace = T, prob = c(0.45,0.55))) Age <- abs(round(rnorm(1000, mean=25, sd=10))+15) Income <- round(rexp(1000,4)*10000,4) df <- data.frame(Name = Name, Sex = Sex, Age = Age, Income= Income) summary(df) |
## Name Sex Age Income ## Valentine: 8 F:436 Min. :10.00 Min. : 8.938 ## Herman : 7 M:564 1st Qu.:33.00 1st Qu.: 692.469 ## Nigel : 7 Median :40.00 Median : 1702.759 ## Booth : 6 Mean :39.76 Mean : 2569.415 ## Chapman : 6 3rd Qu.:47.00 3rd Qu.: 3465.921 ## Edmund : 6 Max. :70.00 Max. :22398.214 ## (Other) :960 |
set.seed(1) i <- sample(1000, 100) j <- sample(1:4, 100, replace = T) df[as.matrix(data.frame(i,j))] <- NA summary(df) |
## Name Sex Age Income ## Valentine: 8 F :424 Min. :10.00 Min. : 8.938 ## Herman : 7 M :551 1st Qu.:33.00 1st Qu.: 698.288 ## Nigel : 7 NA's: 25 Median :40.00 Median : 1709.895 ## Booth : 6 Mean :39.66 Mean : 2584.425 ## Chapman : 6 3rd Qu.:47.00 3rd Qu.: 3476.368 ## (Other) :945 Max. :70.00 Max. :22398.214 ## NA's : 21 NA's :32 NA's :22 |
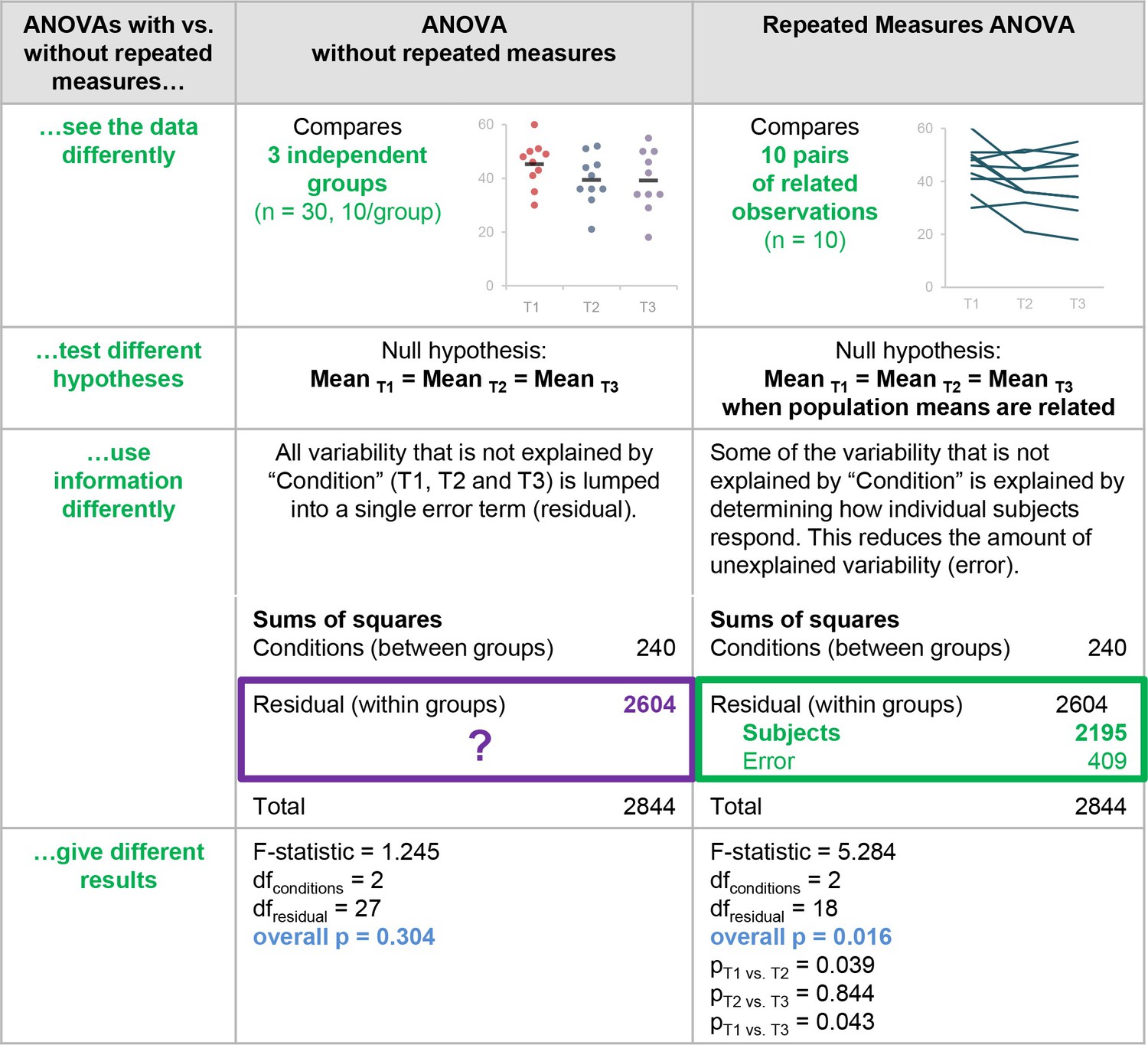
Handle with the dirty data
library(tidyverse) library(VIM) aggr(df, prop = FALSE, numbers = TRUE) |

df2 <- df df2 <- df2[!is.na(df2$Name),] df2 <- replace_na(df2,replace = list(Sex = names(which.max(table(df2$Sex))), Age = mean(df2$Age, na.rm = TRUE))) summary(df2) |
## Name Sex Age Income ## Valentine: 8 F:414 Min. :10.00 Min. : 8.938 ## Herman : 7 M:565 1st Qu.:33.00 1st Qu.: 692.485 ## Nigel : 7 Median :39.69 Median : 1715.361 ## Booth : 6 Mean :39.69 Mean : 2582.242 ## Chapman : 6 3rd Qu.:47.00 3rd Qu.: 3471.288 ## Edmund : 6 Max. :70.00 Max. :22398.214 ## (Other) :939 NA's :22 |
library(mice) imp <- mice(data = df2) |
## ## iter imp variable ## 1 1 Income ## 1 2 Income ## 1 3 Income ## 1 4 Income ## 1 5 Income ## 2 1 Income ## 2 2 Income ## 2 3 Income ## 2 4 Income ## 2 5 Income ## 3 1 Income ## 3 2 Income ## 3 3 Income ## 3 4 Income ## 3 5 Income ## 4 1 Income ## 4 2 Income ## 4 3 Income ## 4 4 Income ## 4 5 Income ## 5 1 Income ## 5 2 Income ## 5 3 Income ## 5 4 Income ## 5 5 Income |
imp$imp |
## $Name ## NULL ## ## $Sex ## NULL ## ## $Age ## NULL ## ## $Income ## 1 2 3 4 5 ## 204 3942.1838 8498.0879 2997.3294 7483.7609 2493.0779 ## 224 838.5253 4868.7148 23.4414 412.1710 583.9495 ## 261 2024.4653 2318.8446 748.2238 788.2074 1234.2818 ## 276 16607.5158 639.4116 727.3643 5756.6726 5760.9782 ## 312 183.4636 7240.4725 1146.3331 37.0536 183.4636 ## 322 6332.3123 1942.6753 127.3307 6321.0070 2293.2614 ## 368 22398.2143 2736.4843 9521.6995 7931.7234 79.5099 ## 371 1934.9597 3462.4594 439.6423 14572.9850 5676.2001 ## 546 13265.6628 2224.4830 1311.7418 6296.6821 6696.6482 ## 610 5087.4181 3050.3740 413.0280 6296.6821 5352.7009 ## 625 6330.5200 886.6474 5123.3427 31.1536 23.4414 ## 650 4894.4728 1301.4659 180.3558 8102.0720 5495.6884 ## 659 71.7279 5108.4458 2476.1572 441.0749 203.0800 ## 694 5296.5679 1757.4108 7764.4984 2563.8153 5126.2661 ## 697 3467.8073 8.9376 183.4636 876.5242 669.4385 ## 780 4868.7148 5455.6900 196.7655 5838.6330 5495.6884 ## 795 24.6374 793.4435 31.1536 413.0280 3467.8073 ## 800 5087.4181 877.4353 373.9559 6296.6821 5352.7009 ## 826 31.1536 4219.5399 3858.1781 230.1099 23.4414 ## 885 23.4414 8837.9920 3005.0820 37.0536 495.0302 ## 906 2410.5120 977.3326 482.9877 4038.2669 3481.2841 ## 917 687.6375 264.4450 6377.2210 1993.9283 3093.6910 |
Income_imp <- apply(imp$imp$Income,1,mean) df2$Income[is.na(df2$Income)] <-Income_imp summary(df2) |
## Name Sex Age Income ## Valentine: 8 F:414 Min. :10.00 Min. : 8.938 ## Herman : 7 M:565 1st Qu.:33.00 1st Qu.: 708.399 ## Nigel : 7 Median :39.69 Median : 1745.223 ## Booth : 6 Mean :39.69 Mean : 2599.971 ## Chapman : 6 3rd Qu.:47.00 3rd Qu.: 3530.039 ## Edmund : 6 Max. :70.00 Max. :22398.214 ## (Other) :939 |
Filling in NAs with last non-NA value
## Sample data x <- c(NA,NA, "A","A", "B","B","B", NA,NA, "C", NA,NA,NA, "A","A","B", NA,NA) goodIdx <- !is.na(x) goodIdx #> [1] FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE TRUE #> [15] TRUE TRUE FALSE FALSE # These are the non-NA values from x only # Add a leading NA for later use when we index into this vector goodVals <- c(NA, x[goodIdx]) goodVals #> [1] NA "A" "A" "B" "B" "B" "C" "A" "A" "B" # Fill the indices of the output vector with the indices pulled from # these offsets of goodVals. Add 1 to avoid indexing to zero. fillIdx <- cumsum(goodIdx)+1 fillIdx #> [1] 1 1 2 3 4 5 6 6 6 7 7 7 7 8 9 10 10 10 # The original vector with gaps filled goodVals[fillIdx] #> [1] NA NA "A" "A" "B" "B" "B" "B" "B" "C" "C" "C" "C" "A" "A" "B" "B" "B" |
fillNAgaps <- function(x, firstBack=FALSE) { ## NA's in a vector or factor are replaced with last non-NA values ## If firstBack is TRUE, it will fill in leading NA's with the first ## non-NA value. If FALSE, it will not change leading NA's. # If it's a factor, store the level labels and convert to integer lvls <- NULL if (is.factor(x)) { lvls <- levels(x) x <- as.integer(x) } goodIdx <- !is.na(x) # These are the non-NA values from x only # Add a leading NA or take the first good value, depending on firstBack if (firstBack) goodVals <- c(x[goodIdx][1], x[goodIdx]) else goodVals <- c(NA, x[goodIdx]) # Fill the indices of the output vector with the indices pulled from # these offsets of goodVals. Add 1 to avoid indexing to zero. fillIdx <- cumsum(goodIdx)+1 x <- goodVals[fillIdx] # If it was originally a factor, convert it back if (!is.null(lvls)) { x <- factor(x, levels=seq_along(lvls), labels=lvls) } x } fillNAgaps(x,firstBack = T) |
## [1] "A" "A" "A" "A" "B" "B" "B" "B" "B" "C" "C" "C" "C" "A" "A" "B" "B" ## [18] "B" |
fillNAgaps(x,firstBack = F) |
## [1] NA NA "A" "A" "B" "B" "B" "B" "B" "C" "C" "C" "C" "A" "A" "B" "B" ## [18] "B" |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles

Comment


