Python is a high-level programming language developed by Guido von Rossum, with applications in numerous areas, including web programming, scripting, scientific computing, and artificial intelligence.
Life is short, you need Python – Bruce Eckel
人生苦短,我用Python
You’ll come across especially data Types quite often, so in this article I‘ll give you all you need to work with python basic data types and some more advanced functions.
¶ntroduction
First, let us check the python version which installed on your computer:
1 2 3 4 5 6 7
python -V ## or wordy ==> python --version ## or more complicated
defshout(word): """ This is a multiline comment to help explain what the docstrings is. A comment designed to explain code. So in this function we wanna print word + !. """ print(word + "!")
shout("hello, world") # hello, world!
Firstly, lemme introduce you python variables, here are some rules:
A variable name should be started with a letter or the underscore character(cannot start with a number) and only contain alpha-numeric characters and underscores (A-z, 0-9, and _ )
(Unicode characters can be used but not recommended.)
import random random.choice(range(10)) ## [0, 9] # 7 random.randrange(1, 10, 2) ## odd number from 1 to 9 # 9 random.random() ## [0, 1) # 0.3568095583272194 random.uniform(1, 10) # 6.91551724782628
## set a random seed to ensure we got the same random ouput random.seed(0) res = random.sample(range(100), 10) ## pick 0-99 res # [49, 97, 53, 5, 33, 65, 62, 51, 38, 61] random.shuffle(res) ## shuffle the result res # [61, 33, 38, 62, 49, 97, 51, 53, 5, 65]
random.seed(1) for i in range(5): value = random.randint(1, 6) # [1, 5] print(value)
1 2 3 4 5
2 5 1 3 1
Logic
Just like other programming languages, python boolean type has only two values too.
Notes: Computers can’t store floats perfectly accurately, in the same way that we can’t write down the complete decimal expansion of 1/3 (0.3333333333333333…).
Keep this in mind, because it often leads to infuriating bugs!
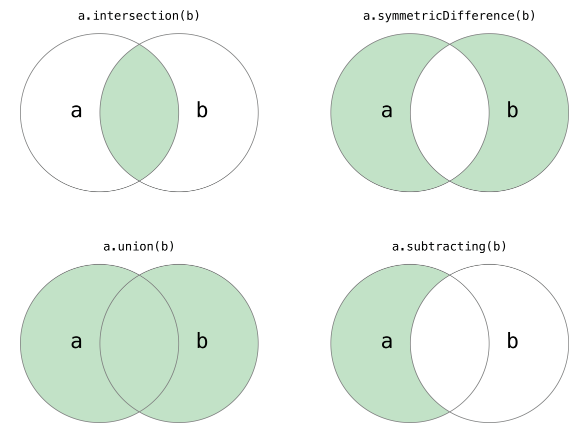
third = first.union(second) third <= first third.issubset(first) first.issuperset(third) # False third >= first first.issubset(third) third.issuperset(first) # True
Dictionaries
Dictionaries are data structures used to map arbitrary keys to values.
Only immutable objects can be used as keys to dictionaries.
1 2 3 4 5 6
fruits = {"apricot": "The bridesmaids wore apricot and white organza", "guava":"have lots of fruits containing Vitamin C like Guava, Oranges, Gooseberries.", "orange":"the citrus species ", "nectarine":"it`s a peach", None: "True", }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
print(fruits['orange']) # the citrus species print(fruits['fruits']) # KeyError: 'fruits' print("orange"in fruits) #== print("orange" in fruits.keys()) # True print("guava"notin fruits) # False print("True"in fruits.values()) # True
print(fruits.get("orange")) # return none if not exists # the citrus species print(fruits.get("banana", 0)) ## KeyError / return 0 if not exists or it will return none # 0
print(fruits["avocado"]) if"avocado"in fruits else"not in dictionary" print(fruits.get("avocado", "not in dictionary")) # not in dictionary
The None object is used to represent the absence of a value.
It is similar to null,nil,undefined in other programming languages.
Like “empty” values, such as 0,(), [] and the empty string
for k, v in fruits.items(): print(k,': ' + v, sep = "") for item in fruits: print(f'{item}: {fruits[item]}')
# apricot: The bridesmaids wore apricot and white organza # guava: have lots of fruits containing Vitamin C like Guava, Oranges, Gooseberries. # orange: the citrus species # nectarine: it`s a peach # None: True
Strings are one of the most basic immutable data types in Programming which used to represent textual data.
In Python, strings are denoted with either single or double quotes or three quotes for explanation.
Strings in Python are immutable. They cannot be modified after being created.
1 2 3 4 5 6 7 8 9
## quotes by Confucius
s1 = 'I hear and I forget. I see and I remember. I do and I understand.' s2 = "I hear and I forget. I see and I remember. I do and I understand." s3 = """ I hear and I forget. I see and I remember. I do and I understand. """ ('\n' + s1 + '\n') == ('\n' + s2 + '\n') == s3 # True
In Chinese:
不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。学至于行之而止矣。
– 《荀子·儒效》
If the strings delimited with single or double quotes within the string, you need to be escaped with a backslash (\) or with the other type of quotes .
alphabet.rpartition(" ") # ('Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Ww Xx Yy',' ','Zz') alphabet.split(maxsplit=5) # ['Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu', 'Vv','Ww','Xx' 'Yy', 'Zz'] ''.split('n') # ['']
num = [1,2,3,4,5] alpha = ['a', 'b', 'c', 'd', 'e'] [print(num[i],alpha[i],sep='-',end=":") for i in range(5)] # 1-a:2-b:3-c:4-d:5-e: [print(list(dict_letters.keys())[i],list(dict_letters.values())[i],sep='-',end=":") for i in range(len(dict_letters))] # A-1:B-2:C-3:D-4:E-5:F-6:G-7:H-8:I-9:J-10:K-11:L-12:M-13:N-14:O-15:P-16:Q-17:R-18:S-19:T-20:U-21:V-22:W-23:X-24:Y-25:Z-26:
Find
Searches the string for a specified value and returns the position of where it was found.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
text = "Can you can a can as a canner can can a can? " text.count('can') # 6 text.count('can', 1, 4) # 0 text.index('can') ## ValueError if not exists text.find('can') ## -1 if not exists # 8 text.rfind('can', 5, 20) # 14
text = "I wish to wish the wish you wish to wish, but if you wish the wish the witch wishes, I won't wish the wish you wish to wish. "
## 5 means 5 times text.replace("wish", "hope", 5) # "I hope to hope the hope you hope to hope, but if you wish the wish the witch wishes, I won't wish the wish you wish to wish. "
startswithendswith
Returns true if the string starts or ends with the specified value.
1 2 3 4 5 6 7
text = '''How many cookies could a good cook cook if a good cook could cook cookies\nA good cook could cook as much cookies as a good cook who could cook cookies''' text.endswith('cookies', 0, 16) ## # Ture text.startswith(('How',"cookies"),0, 16) # True
"dog:{0}, color: {1}".format("huskey", "black and white") # 'dog:huskey, color: black and white' "dog:{1}, color: {0}".format("huskey", "black and white") # 'dog:black and white, color: huskey'
1 2 3 4 5 6 7 8
"dog:{name}, color: {color}".format(name="huskey", color="black and white") # dog:huskey, color: black and white poodle = {"name":"puddle","color":"brown"} "dog:{name}, color: {color}".format(**poodle) # dog:puddle, color: brown dogs = ["Golden Retriever", "Dachshund","shepherd dog","Samoyed"] "dog:{0[1]}, color: {0[2]}".format(dogs) # dog:Dachshund, color: shepherd dog
Lights = {'North': 'aurora borealis', 'South': 'aurora australis'} '{North} colours the night sky through a silhouetted forest'.format_map(Lights) # 'aurora borealis colours the night sky through a silhouetted forest'
Squares and cubes table
1 2 3 4 5
for x in range(1, 11): print(str(x).rjust(2), str(x*x).rjust(3), end=' ') print(str(x*x*x).rjust(4)) for x in range(1, 11): print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
for i in range(1, 10): for j in range(1, i + 1): print('{1}x{0}={2}\t'.format(i, j, i * j), end='') # print('%d*%d=%d' % (i, j, i * j), end='\t') print()
You’re already familiar with the basic python , and now we’re adding some complicated things such as Higher-order function into your python learning mix soups.
Higher-order functions
filter(function or None, sequence) -> list, tuple, or string
Return those items of sequence for which function(item) is true. If function is None, return the items that are true. If sequence is a tuple or string, return the same type, else return a list.
We say simplistic, because python functions quickly get very complicated, and giving it a full treatment now would probably confuse more than help.
We can use for statement for looping over a list - [] 、dict - {}、string - “”, they are Iterable, so these are called iterable objects.
1 2 3 4 5 6 7 8 9
from collections import Iterable ## Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated from collections.abc import Iterable isinstance([], Iterable) isinstance({}, Iterable) isinstance('abc', Iterable) isinstance((x for x in range(10)), Iterable) isinstance(100, Iterable) # False
The built-in function iter takes an iterable object and returns an iterator, so you can give them iter() function, once added they are becoming Iterator.
1 2 3 4 5 6 7 8 9 10
list = [1, 2, 3, 4] it = iter(list) for i in range(2): print (next(it)) # 1 # 2 for x in it: print (x, end=" ") # 3 4 next(it) ## raises a StopIteration.
Generators
Generators are a type of iterable, like lists or tuples.
but unlike lists, they don’t allow indexing with arbitrary indices, although they can be iterated through with for loops.
1 2 3 4 5 6 7 8 9 10
defmeow(n): i = 1 while i < n: yield'meow ' * i i += 1 cat = meow(3) print(next(cat)) print(next(cat)) # meow # meow meow
Generator Expressions
1 2 3 4
(ord(s) for s in"jupyter-lab") # <generator object <genexpr> at 0x000000000503FF48> sum(ord(s) for s in"jupyter-lab") # 1135
A triplet (x, y, z) is called pythogorian triplet if x*x + y*y == z*z.