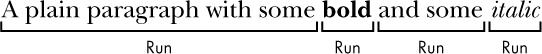Document 对象包含一个 Paragraph 对象的列表,表示文档中的段落, 每个 Paragraph 对象都包含一个 Run 对象的列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
import docx doc = docx.Document('demo.docx') len(doc.paragraphs) # 7 doc.paragraphs[0].text # 'Document Title' doc.paragraphs[1].text # 'A plain paragraph with some bold and some italic' len(doc.paragraphs[1].runs) # 4 doc.paragraphs[1].runs[0].text # 'A plain paragraph with some ' doc.paragraphs[1].runs[1].text # 'bold' doc.paragraphs[1].runs[2].text # ' and some ' doc.paragraphs[1].runs[3].text # 'italic'
利用 getText()函数,可从.docx 文件中取得完整的文本 。
1 2 3 4 5 6 7 8 9
import docx
defgetText(filename): doc = docx.Document(filename) fullText = [] for para in doc.paragraphs: fullText.append(para.text) ## 在段落间增加空行 return'\n\n'.join(fullText)
设置 Paragraph 和 Run 对象的样式
在 Windows 平台的 Word 中,你可以按下 Ctrl-Alt-Shift-S,显示样式窗口并查看样式。
在 OS X 上,可以点击 ViewStyles 菜单项,查看样式窗口。
对于 Word 文档,有 3 种类型的样式:段落样式可以应用于 Paragraph 对象,字符样式可以应用于 Run 对象,链接的样式可以应用于这两种对象。
注意点:
在设置 style 属性时,不要在样式名称中使用空格。
如果对 Run 对象应用链接的样式,需要在样式名称末尾加上’Char’。
Run 属性
通过 text 属性,Run 可以进一步设置样式。每个属性都可以被设置为 3 个值之一:True(该属性总是启用,不论其他样式是否应用于该 Run)、False(该属性总是禁用)或 None(默认使用该 Run 被设置的任何属性)。
属性
描述
bold
文本以粗体出现
italic
文本以斜体出现
underline
文本带下划线
strike
文本带删除线
double_strike
文本带双删除线
all_caps
文本以大写首字母出现
small_caps
文本以大写首字母出现,小写字母小两个点
shadow
文本带阴影
outline
文本以轮廓线出现,而不是实心
rtl
文本从右至左书写
imprint
文本以刻入页面的方式出现
emboss
文本以凸出页面的方式出现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
doc = docx.Document('demo.docx') doc.paragraphs[0].text # 'Document Title' doc.paragraphs[0].style # 'Title' doc.paragraphs[0].style = 'Normal' ## 将Document Title 设置为 Normal 样式
doc.paragraphs[1].text 'A plain paragraph with some bold and some italic' (doc.paragraphs[1].runs[0].text, doc.paragraphs[1].runs[1].text, doc. paragraphs[1].runs[2].text, doc.paragraphs[1].runs[3].text) # ('A plain paragraph with some ', 'bold', ' and some ', 'italic') doc.paragraphs[1].runs[0].style = 'QuoteChar' doc.paragraphs[1].runs[1].underline = True doc.paragraphs[1].runs[3].underline = True doc.save('restyled.docx')