Beautiful Soup, an allusion to the Mock Turtle’s song found in Chapter 10 of Lewis Carroll’s Alice’s Adventures in Wonderland, is a Python library that allows for quick turnaround on pulling data out of HTML and XML files with navigating, searching, and modifying the parse tree.
“Beautiful Soup”出自于刘易斯·卡罗尔 - 《爱丽丝梦游仙境》,第10章中的 The Mock Turtle’s song ,它是一个能够快速从HTML和XML文件中提取 、搜索、修改数据的解析库,使用起来也非常方便。
Installation
首先我们从python分销商那里领取美丽汤,
1 2 3
apt-get install python3-bs4 ## or pip3 install beautifulsoup4 ## or pip install beautifulsoup4
在汤里面放入配料parsers,
1 2 3 4 5 6 7
apt-get install python-lxml ## or pip3 install lxml apt-get install python-html5lib ## or pip3 install html5lib
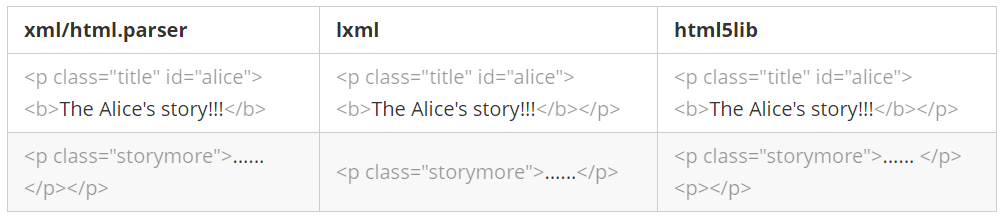
html_doc = """ <!DOCTYPE html> <!-- This is a html file. --> <html lang="en"><head><meta charset="UTF-8" /><title>Alice in Wonderland </title></head> <body> <h1>Alice in Wonderland</h1> <p class="title" id="dormouse"><b>The Dormouse's story!!!</b></p> <pre>start <span>initialize the story</span><i> end</i></pre> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> <p class="title" id= "alice"> <b>The Alice's story!!!</b> <p class="story1">1.<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a></p> <p class="story2">2.<a href="http://example.com/tears" id="link5">The Pool of Tears</a></p> <p class="story3">3.<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a></p> <p class="storymore">......</p> </p> </html> """
## let us make a soup soup = BeautifulSoup (html_doc,"xml") lsoup = BeautifulSoup (html_doc,"lxml")
## This will prettify the html document. print (soup.prettify ()) ## str(soup) non-pretty print print(lsoup)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<!DOCTYPE html> <!-- This is a html file. --><htmllang="en"><head><metacharset="utf-8"/><title>Alice in Wonderland </title></head> <body> <h1>Alice in Wonderland</h1> <pclass="title"id="dormouse"><b>The Dormouse's story!!!</b></p> <pre>start <span>initialize the story</span><i> end</i></pre> <pclass="story">Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1">Elsie</a>, <aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and <aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <pclass="story">...</p> <pclass="title"id="alice"> <b>The Alice's story!!!</b> </p><pclass="story1">1.<ahref="http://example.com/rabbit"id="link4">Down the Rabbit-Hole</a></p> <pclass="story2">2.<ahref="http://example.com/tears"id="link5">The Pool of Tears</a></p> <pclass="story3">3.<ahref="http://example.com/tale"id="link6">A Caucus-Race and a Long Tale</a></p> <pclass="storymore">......</p> </body></html>
Basic Usage
We’ll take this article from Alice in Wonderland using lxml and xml:
for tag in tSoup.find_all('div'): print(tag(text=True)) # ['title', 'p'] # ['title', 'div'] # ['div'] for tag in tSoup.find_all('div'): print(tag(text=False)) # [<p>p</p>] # [<div>div</div>] # [] for tag in tSoup.find_all('div'): print(tag.text) # titlep # titlediv # div for tag in tSoup.find_all('div'): print(tag.string) # None # None # div
soup.find(text=re.compile("sisters")) # text contain sisters soup.find(string=re.compile("sisters")) # 'Once upon a time there were three little sisters; and their names were\n' soup.find_all(text=re.compile("A")) # ['Alice in Wonderland ', # 'Alice in Wonderland', # "The Alice's story!!!", # 'A Caucus-Race and a Long Tale'] soup.find_all(href=re.compile("elsie"), id='link1') soup.find_all(href="http://example.com/elsie", id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] for tag in soup.find_all(re.compile("^b")): print(tag.name) # body # b # b for tag in soup.find_all(re.compile("\w{2}t")): print(tag.name) # meta # title
for link in soup.find_all('a'): print(link.get('href')) for link in soup.find_all('a'): print(link['href']) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie # http://example.com/rabbit # http://example.com/tears # http://example.com/tale
for text in soup.find_all("p"): print(text.text) for text in soup.body.find_all("p",recursive=True): print(text.get_text()) ## xml # The Dormouse's story!!! # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # ...
# The Alice's story!!! # 1.Down the Rabbit-Hole # 2.The Pool of Tears # 3.A Caucus-Race and a Long Tale # ......
# 1.Down the Rabbit-Hole # 2.The Pool of Tears # 3.A Caucus-Race and a Long Tale # ......
## lxml # The Dormouse's story!!! # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # ...
# The Alice's story!!!
# 1.Down the Rabbit-Hole # 2.The Pool of Tears # 3.A Caucus-Race and a Long Tale # ......
for text in soup.find_all("p"): print(text.string) The Dormouse's story!!! # None # ... # None # None # None # None # ......
from bs4 import Comment new_comment = tree.new_string("Nice to see you.", Comment) # <class 'bs4.element.Comment'> tag.i.insert_after(new_comment) tag.append("ever") tag.name="p" print(tag) # <p>No longer bold<i>Nothing</i><!--Nice to see you.-->ever</p> tag.i.insert(1,new_comment) print(tag) # <p>No longer bold<i>Nothing<!--Nice to see you.--></i>ever</p> tag.find_all(text=lambda text:isinstance(text, Comment)) # ['Nice to see you.'] tag.clear() # removes the contents print(tag) # <p></p>
tag.string="I wish I was bold" tag.string.wrap(tree.new_tag("b",id="id1 id2")) tag.b['class'] = ['class1', 'class2'] print(tag) # <p><b class="class1 class2" id="id1 id2">I wish I was bold</b></p> ## select用于传入一个字符串作为CSS选择器 tag.select("b.class1.class2") # [<b class="class1 class2" id="id1 id2">I wish I was bold</b>] print(tag.b["class"]) # rel, rev, accept-charset, headers, and accesskey are list # ['class1', 'class2'] print(tag.b["id"]) # id1 id2 print(tag.b.get_attribute_list("id")) # ['id1 id2']
# Note: If you parse a document as XML, there are no multi-valued attributes:
tag.b.unwrap() print(tag) # <p>I wish I was bold</p>
for i, child in enumerate(soup.p.children): print(i, child) # 0 <b>The Dormouse's story!!!</b> for parent in soup.a.parents: if parent isNone: print(parent) else: print(parent.name) # p # body # html # [document] len(list(lsoup.descendants)) len(list(soup.descendants)) # 63 list(soup.children)==soup.contents # children = contents # True for child in soup.descendants: # all of a tag’s children, recursively print(child)
list(soup.stripped_strings) # ['Alice in Wonderland', # 'Alice in Wonderland', # "The Dormouse's story!!!", # 'start', # 'initialize the story', # 'end', # 'Once upon a time there were three little sisters; and their names were', # 'Elsie', # ',', # 'Lacie', # 'and', # 'Tillie', # ';\nand they lived at the bottom of a well.', # '...', # "The Alice's story!!!", # '1.', # 'Down the Rabbit-Hole', # '2.', # 'The Pool of Tears', # '3.', # 'A Caucus-Race and a Long Tale', # '......'] for i, parent in enumerate(list(soup.body.parent)): print(i, parent) # 0 <head><meta charset="UTF-8"/><title>Alice in Wonderland </title></head> # 1
# 2 <body> # <h1>Alice in Wonderland</h1> # <p class="title" id="dormouse"><b>The Dormouse's story!!!</b></p> # <pre>start <span>initialize the story</span><i> end</i></pre> # <p class="story">Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; # and they lived at the bottom of a well.</p> # <p class="story">...</p> # <p class="title" id="alice"> # <b>The Alice's story!!!</b> # <p class="story1">1.<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a></p> # <p class="story2">2.<a href="http://example.com/tears" id="link5">The Pool of Tears</a></p> # <p class="story3">3.<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a></p> # <p class="storymore">......</p> # </p> # </body> print(list(enumerate(soup.a.next_siblings))) # [(0, ',\n'), (1, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>), (2, ' and\n'), # (3, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>), (4, ';\nand they lived at the bottom of a well.')] soup.h1.next_element # 'Alice in Wonderland' list(soup.a.next_siblings) # [',\n', # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # ' and\n', # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, # ';\nand they lived at the bottom of a well.'] list(soup.find(id="alice").next_siblings) # ['\n'] soup.find("a", id="link3").next_element # 'Tillie' soup.h1.next_element # 'Alice in Wonderland' soup.h1.previous_element # '\n' soup.find(string="Lacie").find_parents("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] soup.find(string="Lacie").find_parent("p") # <p class="story">Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; # and they lived at the bottom of a well.</p> soup.a.find_next_siblings("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find("p", "story").find_next_sibling("p") # <p class="story">...</p> soup.a.find_all_next(string=True) # ['Elsie', u',\n', u'Lacie', u' and\n', u'Tillie', # ';\nand they lived at the bottom of a well.', u'\n\n', u'...', u'\n'] soup.a.find_next("p") # <p class="story">...</p> soup.h1.find_next("i") # <i> end</i> soup.find(id="link3").find_all_previous("a") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] for p in lsoup.find_all(name='p'): print(p.find_all(name='a')) for a in p.find_all(name='a'): print(a.string) # [] # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # Elsie # Lacie # Tillie # [] # [] # [<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a>] # Down the Rabbit-Hole # [<a href="http://example.com/tears" id="link5">The Pool of Tears</a>] # The Pool of Tears # [<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a>] # A Caucus-Race and a Long Tale # []
defhas_class_but_no_id(tag): return tag.has_attr('class') andnot tag.has_attr('id') soup.find_all(has_class_but_no_id) # [<p class="story">Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; # and they lived at the bottom of a well.</p>, # <p class="story">...</p>, # <p class="story1">1.<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a></p>, # <p class="story2">2.<a href="http://example.com/tears" id="link5">The Pool of Tears</a></p>, # <p class="story3">3.<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a></p>, # <p class="storymore">......</p>] defnot_lacie(href): return href andnot re.compile("lacie").search(href) soup.find_all(href=not_lacie) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, # <a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a>, # <a href="http://example.com/tears" id="link5">The Pool of Tears</a>, # <a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a>] defhas_six_characters(css_class): return css_class isnotNoneand len(css_class) == 6 soup.find_all(class_=has_six_characters) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, # <p class="story1">1.<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a></p>, # <p class="story2">2.<a href="http://example.com/tears" id="link5">The Pool of Tears</a></p>, # <p class="story3">3.<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a></p>] defis_the_only_string_within_a_tag(s): # ""Return True if this string is the only child of its parent tag."" return (s == s.parent.string) soup.find_all(text=is_the_only_string_within_a_tag) # ['Alice in Wonderland ', # 'Alice in Wonderland', # "The Dormouse's story!!!", # 'initialize the story', # ' end', # 'Elsie', # 'Lacie', # 'Tillie', # '...', # "The Alice's story!!!", # 'Down the Rabbit-Hole', # 'The Pool of Tears', # 'A Caucus-Race and a Long Tale', # '......']
from bs4 import NavigableString defsurrounded_by_strings(tag): return (isinstance(tag.next_element, NavigableString) and isinstance(tag.previous_element, NavigableString))
for tag in soup.find(id="alice").find_all(surrounded_by_strings): print(tag.name) # b # p # a # p # a # p # a # p
CSS
lxml supports “.” “#” xml otherwise do not support
## Find tags by CSS ID: print(soup.select("a#link2")) # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] print(soup.select('p[id="alice"]')[0].get_text("|",strip=True)) # The Alice's story!!!|1.|Down the Rabbit-Hole|2.|The Pool of Tears|3.|A Caucus-Race and a Long Tale|......
## Find the a by href: print(soup.select('a[href]')==soup.find_all("a")) # True
soup.select('a[href*="http://example.com/t"]') # exact attribute middle match # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, # <a href="http://example.com/tears" id="link5">The Pool of Tears</a>, # <a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a>] soup.select('a[href$="t"]') # [<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a>]
## Find the elements a by pesudo select: print(soup.select("p:nth-of-type(4)")) # [<p class="title" id="alice"> # <b>The Alice's story!!!</b> # <p class="story1">1.<a href="http://example.com/rabbit" id="link4">Down the Rabbit-Hole</a></p> # <p class="story2">2.<a href="http://example.com/tears" id="link5">The Pool of Tears</a></p> # <p class="story3">3.<a href="http://example.com/tale" id="link6">A Caucus-Race and a Long Tale</a></p> # <p class="storymore">......</p> # </p>]
soup = BeautifulSoup(open("Alice.html")) with open("Alice.html") as fp: soup = BeautifulSoup(fp) ## The default is formatter="minimal". To ensure that Beautiful Soup generates valid HTML/XML: print(soup.prettify(formatter="minimal")) ## Convert Unicode characters to HTML entities whenever possible ## if formatter=None, Beautiful Soup will not modify strings at all on output. print(soup.prettify(formatter="html"))