排序算法
排序算法可以分为内部排序和外部排序。
内部排序是在内存数据记录中进行排序。
外部排序需要访问外存,因排序的数据很大,一次不能容纳全部的排序记录。
常见的内部排序算法有用一张图概括如下:
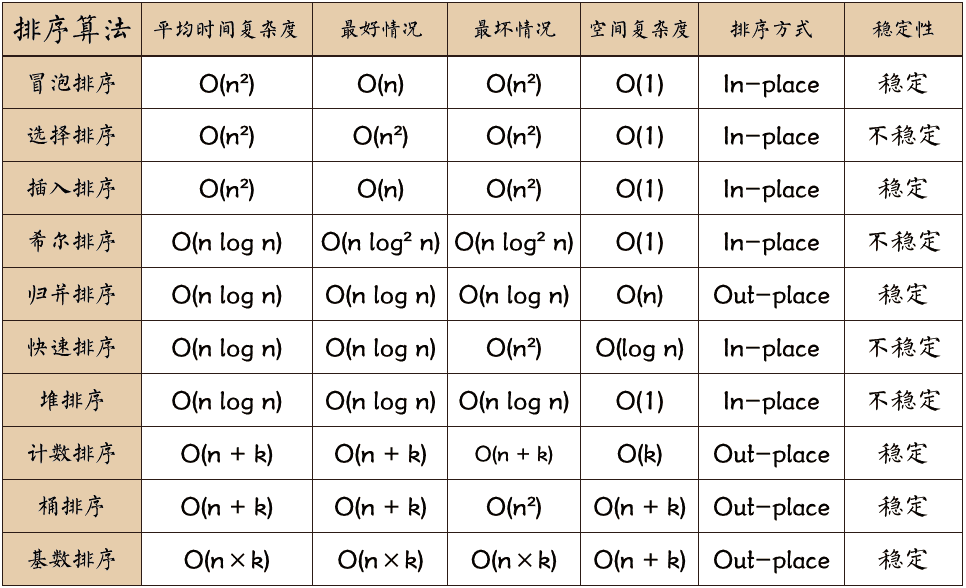
1 | """ |
热身
设计一个函数返回传入的列表中最大和第二大以及最小和第二小的元素的值。
1 | def maxmin2(x): |
冒泡排序(Bubble sort)
我们先看一个简单的例子:
1 | array = [1, 2, 5, 3, 6, 8, 4] |
我们再使用swapped变量优化一下以上算法,判断当前数组是否已排序,减少多余的循环。同时传入comp参数进行排序选择。
1 | def bubble_sort(items, comp=lambda x, y: x > y): |
这里我们换一个思路,通过传入一个*numbers可变参数,通过比较num[j] 和 num[i]进行冒泡排序:
1 | def bubble_sort2(*numbers): |
1 | [3, '< 1?'] |
双向冒泡排序(也称鸡尾酒排序、搅拌排序)
双向冒泡排序,在完成一次从左往右的冒泡排序后,再从右往左进行冒泡,从而把小的元素放在左边。
1 | def bubble_sort(items, comp=lambda x, y: x > y): |
快速排序
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
1 | def partition(arr,low,high): |
1 | def quick_sort(items, comp=lambda x, y: x <= y): |
选择排序
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
1 | def select_sort(items, comp=lambda x, y: x < y): |
归并排序
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。
1 | def merge_sort(items, comp=lambda x, y: x <= y): |
1 | def merge(items1, items2, comp): |
插入排序(Insertion Sort)
- 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
1 | def insertionSort(arr): |
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序(间隔减半),待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
1 | def shellSort(arr): |
堆排序
- 创建一个堆 H[0……n-1];
- 把堆首(最大值)和堆尾互换;
- 把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
- 重复步骤 2,直到堆的尺寸为 1。
从列表中找出最大的或最小的N个元素
堆结构(大根堆/小根堆)
1 | import heapq |
1 | [99, 92, 88] |
计数排序
- 花O(n)的时间扫描一下整个序列 A,获取最小值 min 和最大值 max
- 开辟一块新的空间创建新的数组 B,长度为 ( max - min + 1)
- 数组 B 中 index 的元素记录的值是 A 中某元素出现的次数
- 最后输出目标整数序列,具体的逻辑是遍历数组 B,输出相应元素以及对应的个数
桶排序
- 设置固定数量的空桶。
- 把数据放到对应的桶中。
- 对每个不为空的桶中数据进行排序。
- 拼接不为空的桶中数据,得到结果
基数排序
- 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零
- 从最低位开始,依次进行一次排序
- 从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列
REFERENCES
- 程序员小吴 [wx:五分钟学算法](javascript:void(0)😉 十大经典排序算法动画与解析,看我就够了!(配JAVA代码完全版
- 15 种排序算法可视化展示: https://www.runoob.com/w3cnote/15-sorting-algorithms-visually-displayed.html
- 8种可视化展示 : https://www.toptal.com/developers/sorting-algorithms
- Wiki
- 菜鸟教程
- https://github.com/jackfrued/Python-100-Days/blob/master/Day16-20/16-20.Python语言进阶.md
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles



Comment

